Graphql Read From Cache Before Server Query
Tips and Tricks for working with Apollo Cache
With its declarative fetching, helpful tooling, extensive blazon definitions, and built-in integration with React, Apollo Customer has played a cardinal office in simplifying frontend architecture over the past few years. Its congenital-in caching layer, which allows you to think previously requested data without needing to make boosted network requests to the server, has the potential to make any application feel snappier. Apollo even provides means of warming upwards the cache to exist used for afterward, freeing our frontends from the dreaded loading spinners.
But cache invalidation is one of those notoriously difficult bug in whatsoever computer program, and trying to update or bosom Apollo's cache later on server-side updates is far from a perfect experience, particularly when the queries existence cached have many filters and constraints. Let's begin with an overview of how Apollo's cache works, and then discuss the tradeoffs involved with a few different approaches to working with it.
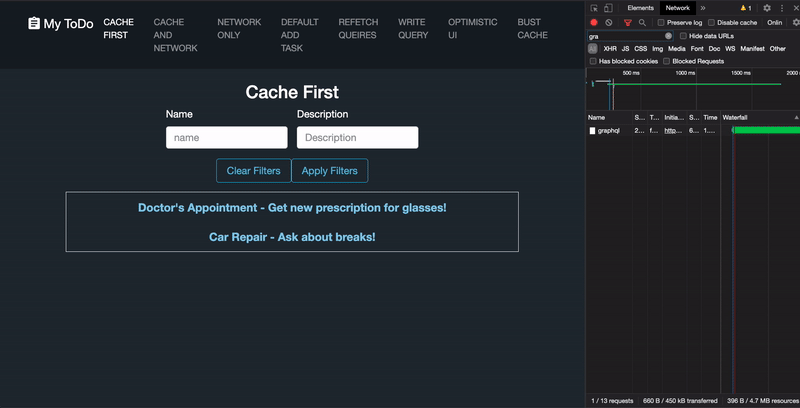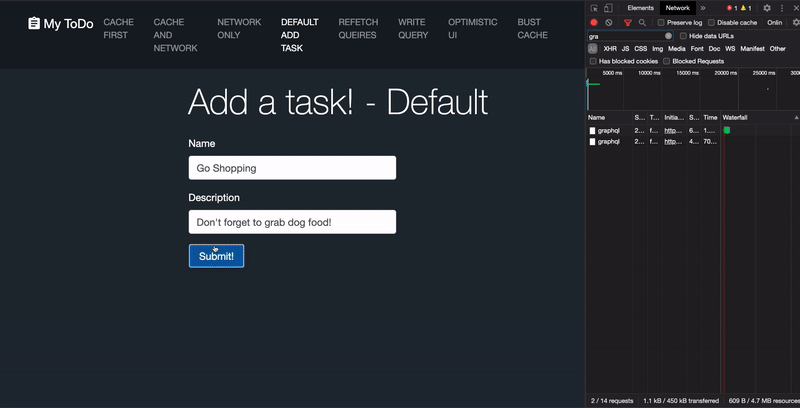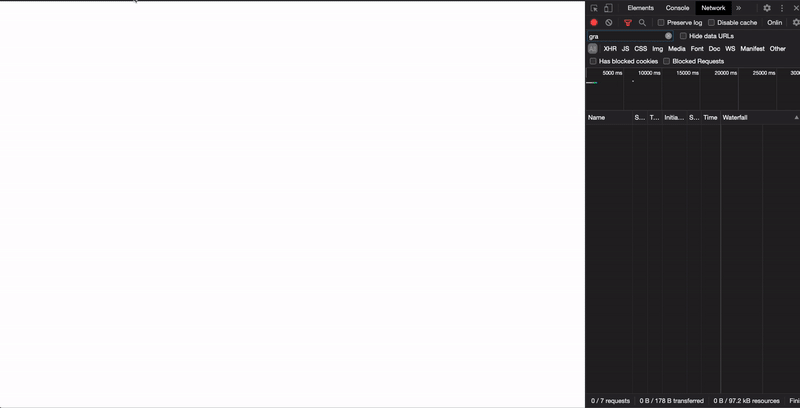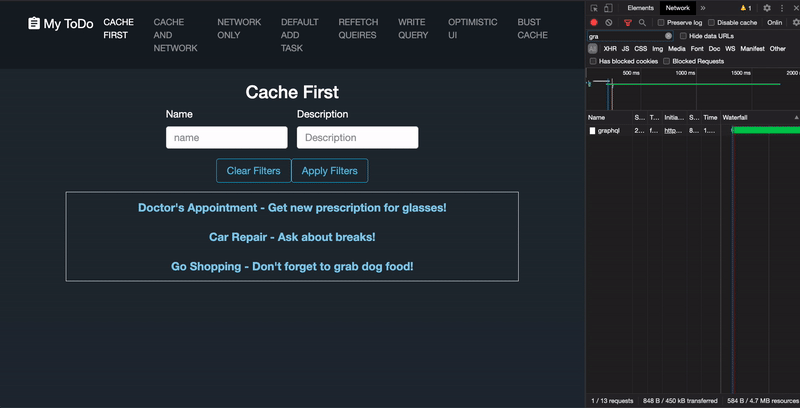
Throughout this article we'll be using this Mock List application every bit a reference.
Cache Keys
When you make whatsoever graphQL query, by default Apollo caches the response in what it calls a flat, normalized lookup table. It constructs a unique identifier for each object returned from your query, past combining its id or _id backdrop with the __typename defined in your schema.
And so if the application to a higher place executes queries as the user types "G", then "Go", then "Go g", all the way to "Go groceries shopping", Apollo could potentially pull down information most many different tasks and enshroud each one roughly like this:
Task:1234: { name: "Become grocery shopping" }
Task:2345: { proper name: "Go to gym" }
Task:3456: { proper name: "Learn GoLang" } This is great if the user navigates to a detail view about a given job, considering in that location volition already be some information immediately available.
Apollo will besides store the results of each of those individual queries, in example you make the same exact query again later on. That data is stored in Apollo'south enshroud, based on the name of the query yous execute, as well equally whatsoever variables you lot pass to information technology, like this:
ROOT_QUERY:
tasks(name: "Thou"): [{}, {}, {}]
tasks(name: "Go"): [{}, {}, {}]
tasks(proper name: "Gol"): [{}] If a user adds a new task or updates an existing chore, then Apollo will update the respective single cache key for that individual job, but unless you tell it exactly what you desire it to practise, it won't know which collection queries needs to be updated or invalidated. There are several means to handle this.
Fetch Policies
The easiest workaround by far is to customize the fetchPolicy for your collection queries. The following are the list of fetch policies that you can specify for your query:
- enshroud-beginning
- cache-and-network
- network-only
- no-enshroud
- cache-simply
For the purpose of this article, we'll only exist discussing the first three as they are more likely to be used.
cache-first
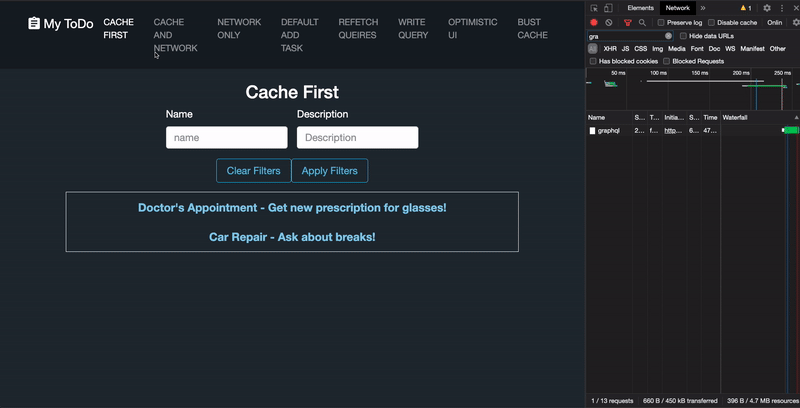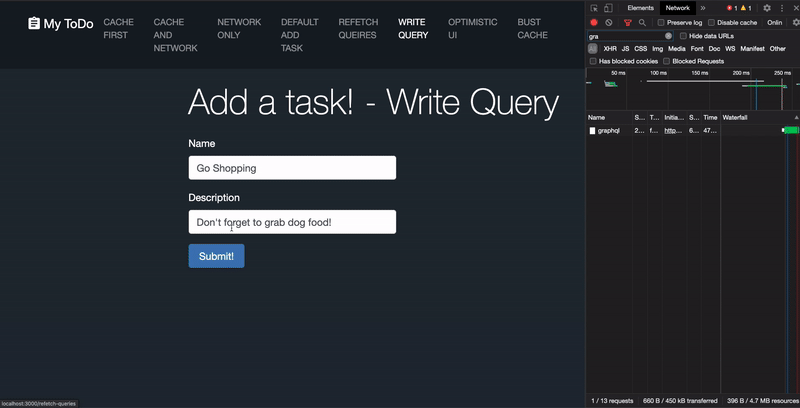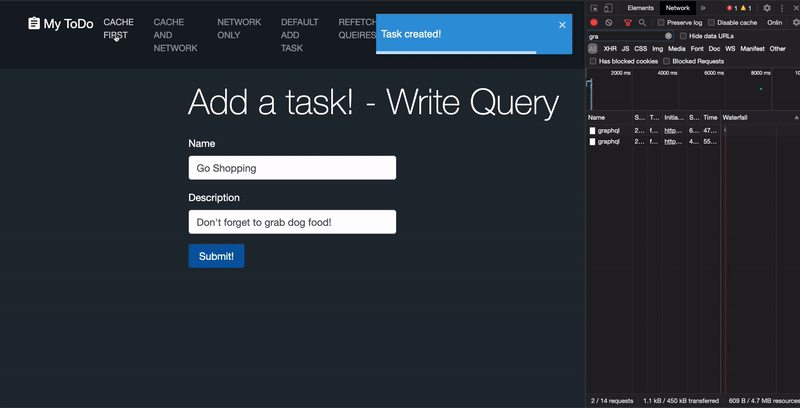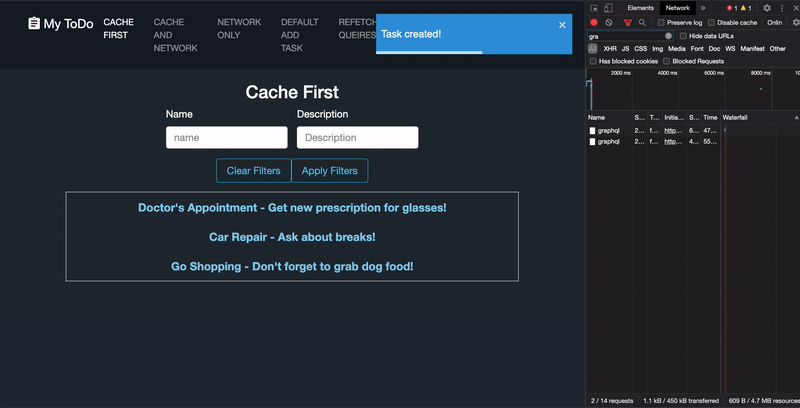
This is the default. Apollo volition first wait in the cache to see if there is a query matching the given proper noun and filters, and if and so, it will call back information technology; otherwise, it volition brand a network request. The drawback to this method lies with its inability to recognize server-side changes to the data. As data changes on the backend, you will accept to manually modify the cache using a dissimilar Apollo method to have the query reflect any updates.
cache-and-network
This policy behaves the aforementioned equally enshroud-first, but even if Apollo does locate an existing response in the enshroud, it will still make a network asking in the background and update the cache (and in turn, the UI) if the response differs from what it has stored. This provides the user with some information right away, and potentially more than accurate information later on the query returns.
For many unproblematic applications this will be enough. Nonetheless for applications that require 100% accuracy, or for larger, more than complex applications with very expensive queries, this may not be a suitable solution every bit Apollo volition always be making a query in the background and that tin crusade operation bug for the frontend.
network-only
With this policy, Apollo will bypass the cache and e'er make a network asking. Notwithstanding it volition still store the result of the request in the cache in case the same query with a different fetch policy is being made elsewhere in the application. This is the easiest solution to making sure your app volition always have the nearly upwardly-to-engagement data. The problem is nosotros've at present bypassed the caching feature and volition lose out on that snappy feeling and will end upwardly having to prove loading wheels more often through out the app. Depending on your client'due south needs, this may not be acceptable.
Refetch Queries
Consider the following query claw:
useQuery(FETCH_TASKS, { variables: { proper name: input } }) This query retrieves a collection of task records and accepts a proper name variable to filter the list down. Each time the name filter is updated, Apollo will shop the server response for that name in its cache individually.
When new tasks are added to the data store, nosotros can tell Apollo to refetch whatever previous FETCH_TASKS query results in its cache similar this:
useMutation(
CREATE_TASK,
{
refetchQueries: [getOperationName(FETCH_TASKS)]
}
) 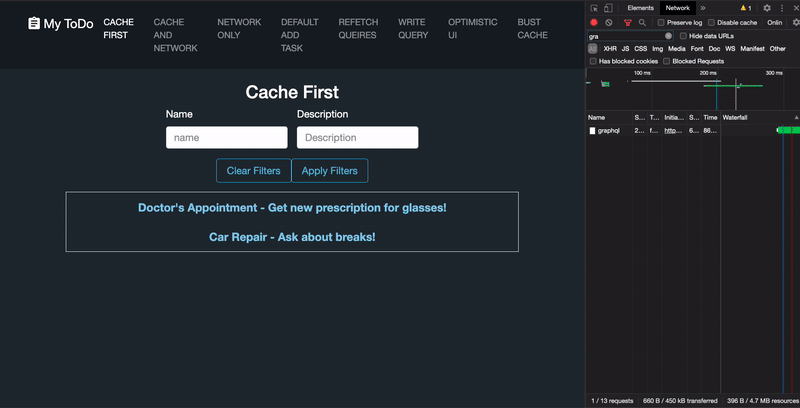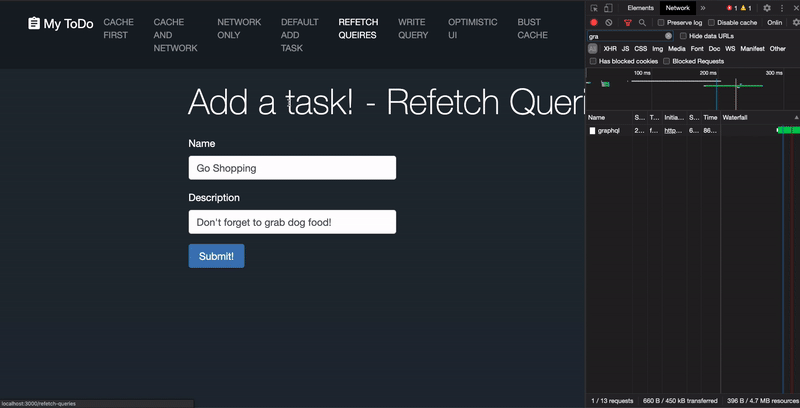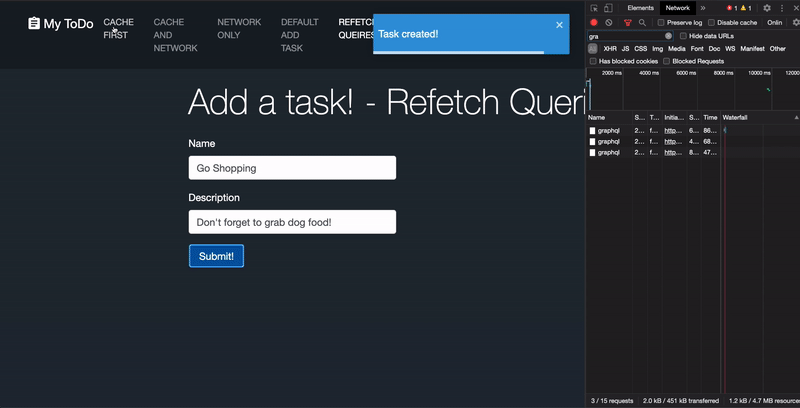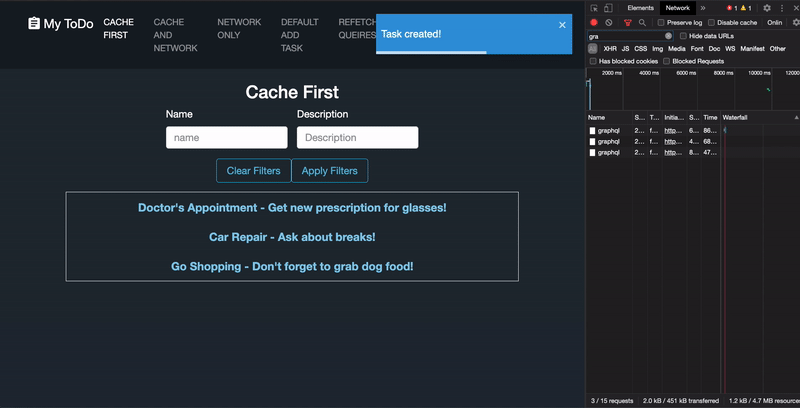
This mode, if a user tends to search for particular data again and again, they can be confident they are receiving the most current results. Yet, this particular approach will just work if the component that made the originalFETCH_TASKS query is withal mounted. Also, any queries with the same operation name will exist refetched simultaneously. So you have over 100+ queries with the aforementioned operation proper noun in the cache, they will all be refetched at one time, which tin can be easily bear upon the performance of your application
It's also possible to refresh a more targeted subset of queries, like this:
useMutation(
CREATE_TASK,
{
refetchQueries: [
{ query: FETCH_TASKS, { variables: { name: 'shopping' } } }
]
}
) Just this approach can become problematic when in that location are additional filters that go passed to the query as variables, and y'all accept to make up one's mind which permutations will require refetching — or when at that place are pagination considerations with cascading off-by-one errors when a new record gets inserted in the middle of a list. Refetches are however done simultaneously, which tin can have performance implications.
Because of these difficulties, Apollo provides multiple means to update the cache manually, depending on the needs to your application.
Writing to the Cache
Apollo provides us a way to latch onto the success of a mutation, so we tin bypass refetching and write directly to the cache and update specific query results.
This approach eliminates unnecessary network traffic, because knowing the mutation's upshot often enables yous to determine how the enshroud (and UI) should be updated accordingly.
useMutation(CREATE_TASK, {
update: (cache, mutationResult) => {
const newTask = mutationResult.data.createTask;
const data = cache.readQuery({
query: FETCH_TASKS, variables: { proper noun: newTask.proper name }
});
cache.writeQuery({
query: FETCH_TASKS,
variables: { name: newTask.name },
data: { tasks: [...information.tasks, newTask]
})
}
}) The update callback is triggered once the mutation has finished. The first statement supplied will be the Apollo cache, and the 2d will be the mutation result object.
The enshroud is capable of reading the result of any existing query in the shop via readQuery and then we can update the cache with new data from out mutation issue using writeQuery.
If we know nosotros want the new task to be appended to the end of a listing, this code will attain that chore for theFETCH_TASKS query for an exact match on that new task'south proper noun. Unfortunately, if results are sorted in a detail way or paginated server-side, there is no convenient style to find where this new record fits without duplicating a off-white fleck of logic.
Also, if we want to update the enshroud for fractional matches, we would have to iterate through each potential match ("K", "Go", Gol", and so on). Complicating matters further, it's important to note that readQuery throws an error if a given query isn't in the cache yet, so a robust implementation with unlike combinations of variables would need to be wrapped in a fair scrap of provisional logic or effort / catching.
Optimistic UI
For fairly simple cases, when writing directly to the cache is feasible, and the result of a given mutation is predictable, Apollo gives us a way to update the UI fifty-fifty before the network request returns a response! This can be a game changer for users who have boring internet connections.
When the server does ultimately respond, the optimistic upshot will be replaced by the actual result. If the mutation fails, the optimistic result will be discarded.
useMutation(CREATE_TASK, {
update: (cache, mutationResult) => {
const newTask = mutationResult.information.createTask;
const data = cache.readQuery({
query: FETCH_TASKS, variables: { name: newTask.proper name }
});
cache.writeQuery({
query: FETCH_TASKS,
variables: { proper name: newTask.name },
data: { tasks: [...data.tasks, newTask]
})
},
optimisticResponse: {
__typename: "Mutation",
createTask: {
__typename: "Task",
_id: `This role we don't know yet but it will be a unique cord so just to be prophylactic ${uuid()}`,
name: input.proper noun,
description: input.description,
}
}
}) It'due south important that the optimisticResponse includes the expected __typename property, both for the mutation itself and for whatever information the mutation returns. In this example, it's possible to infer most all the information the server will return from the user'south input, with the exception of its _id, because this is assigned on the server. This is fine so long as we are careful to assign a unique cord that can be replaced once the server does assign a valid id.
In additional to the other issues detailed with writeQuery, these are two other problems that I've experienced using this method:
1. You may not e'er know the result of the mutation, therefore an optimistic issue cannot be inferred. If the data that the frontend works with gets massaged by several middleware layers earlier getting persisted, it may look entirely different in ways that are impossible to predict.
2. A successful mutation may not hateful that the data was successfully persisted. If your information goes through multiple middleware orchestration layers, and the server may send a successful response back afterwards getting past the first workflow, and do additional processing in the background. In these cases, the frontend won't know if insertion failed at a after point. This may be a proficient case for subscriptions, but that's a topic for another mail.
Busting the Cache
The terminal method we'll be discussing is the one that'southward worked the best for me personally. In improver to existence able to read / write to the Apollo enshroud, if you are on Apollo Customer 3.0 or higher, you tin can besides easily evict specific sets of cache keys when a mutation succeeds.
Post-obit this strategy, Apollo volition be forced to refetch certain queries if the user re-requests them, but won't trigger potentially hundreds of requests just considering a user might re-request them later. And this allows us to leave the default fetchPolicy in place so that we can benefit from caching when the user is not adding data via mutations.
useMutation(CREATE_TASK, {
update: enshroud => {
cache.evict({
id: "ROOT_QUERY",
field: "tasks"
})
}
} This code assumes we want to affluent out whatsoever responses to whatsoever queries that are cached via the tasks key simply we tin can also exist more targeted if we like.
useMutation(CREATE_TASK, {
update: (cache, mutationResult) => {
const newTask = mutationResult.information.createTask;
cache.evict({
id: "ROOT_QUERY",
field: "tasks",
args: { proper name: newTask.name }
})
}
}) Conclusion
To wrap things up, none of these solutions are "perfect". No powerful tool is always perfect. But the Apollo squad has given us a broad menu of options to choice from to match against our intended use case. Yous will likely demand to play around with a few of them to determine which i best suits your awarding, but I am confident y'all will be able to fashion a workable solution to your problem out of the tools provided in the latest Apollo release.
The Apollo Data Graph Platform or "Apollo Customer" software is the holding of and a registered trademark of Apollo Graph Inc.
Source: https://medium.com/rbi-tech/tips-and-tricks-for-working-with-apollo-cache-3b5a757f10a0
0 Response to "Graphql Read From Cache Before Server Query"
Postar um comentário